In the previous article we have seen how to use Elasticsearch for indexing and querying for code documents. But it's not interesting on an empty search index. What's left is feeding the Code Search Service with Code Documents!
Each code document to be indexed has the following data:
- Id
- Repository Owner
- Repository Name
- Path
- Filename
- Commit Hash
- Content
- Permalink
- Latest Commit Date
So let's see how we can get a list of repositories and how to get all the metadata required.
We will write a small PowerShell script for it.
All code in this article can be found at:
Table of contents
What we are going to build
The final result is a Search Engine, that allows us to search for code and sort the results by name, date and other fields. The idea is to index all repositories of an owner, such as Microsoft, and search code through their repositories.
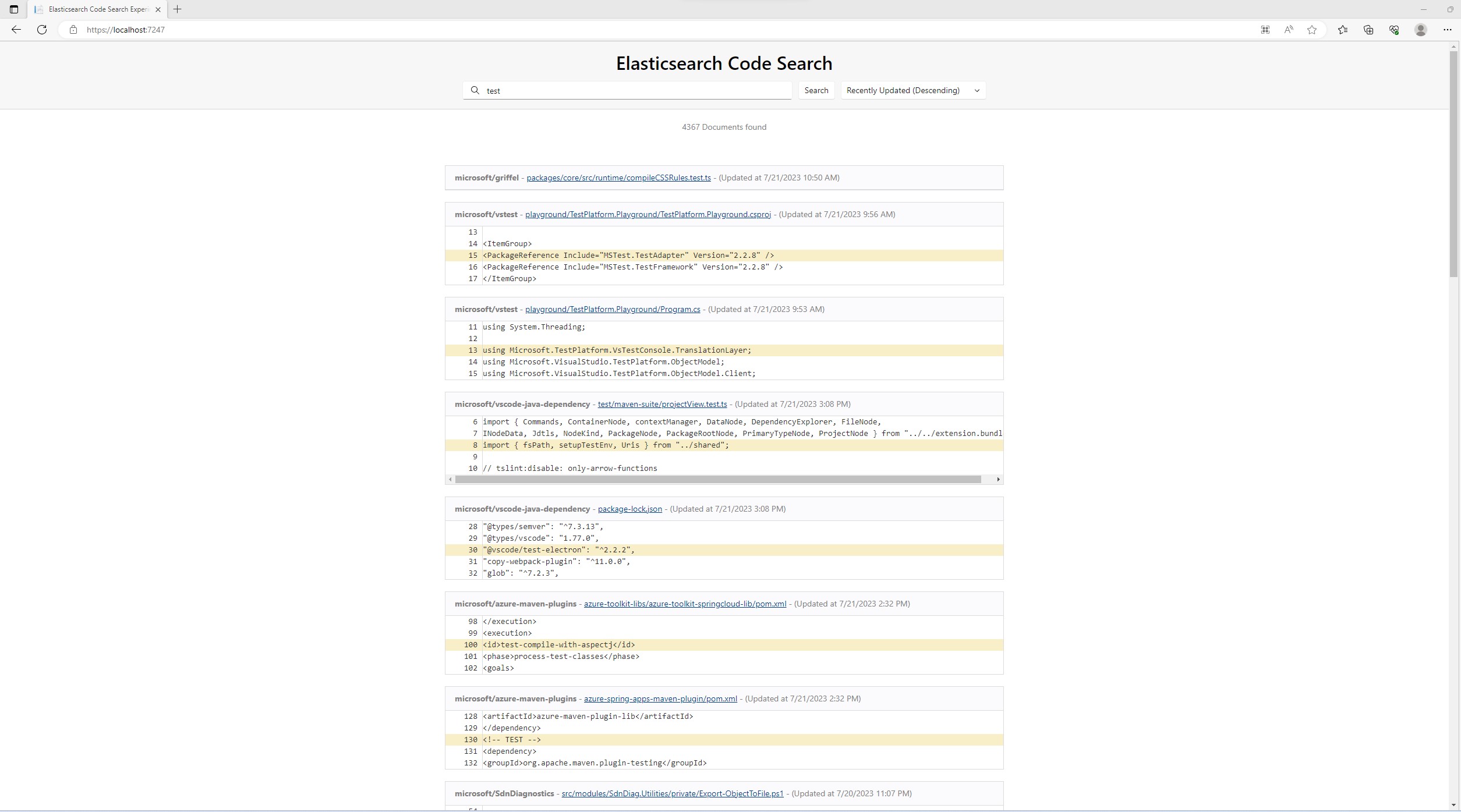
Getting a list of Git repositories for an owner
It all starts with getting a list of Git repositories for an owner. An owner is either an organization or a user in GitHub. Instead of fiddling around with the GitHub API, we can use the GitHub CLI, which is available at:
The gh repo list command is used to list the repositories of an owner. The GitHub CLI allows
us to filter for a subset of properties and return the results as JSON, so it's nicer to work
with in Powershell.
Here is a PowerShell example for getting a list of Microsoft's repositories:
PS C:\Users\philipp> gh repo list microsoft --json id,name,languages,url,sshUrl
[
{
"id": "R_kgDOH9-6Vw",
"languages": [
{
"size": 151982,
"node": {
"name": "C#"
}
}
],
"name": "m365-developer-proxy",
"sshUrl": "git@github.com:microsoft/m365-developer-proxy.git",
"url": "https://github.com/microsoft/m365-developer-proxy"
},
{
"id": "MDEwOlJlcG9zaXRvcnkxOTcyNzU1NTE=",
"languages": [],
"name": "winget-pkgs",
"sshUrl": "git@github.com:microsoft/winget-pkgs.git",
"url": "https://github.com/microsoft/winget-pkgs"
},
{
"id": "MDEwOlJlcG9zaXRvcnk2MzQ0MTI3Mw==",
"languages": [
{
"size": 11681031,
"node": {
"name": "C#"
}
},
{
"size": 2812,
"node": {
"name": "Batchfile"
}
},
{
"size": 4836,
"node": {
"name": "Smalltalk"
}
},
{
"size": 10828,
"node": {
"name": "PowerShell"
}
},
{
"size": 5075,
"node": {
"name": "Shell"
}
},
{
"size": 1826764,
"node": {
"name": "TSQL"
}
},
{
"size": 506,
"node": {
"name": "Jupyter Notebook"
}
}
],
"name": "sqltoolsservice",
"sshUrl": "git@github.com:microsoft/sqltoolsservice.git",
"url": "https://github.com/microsoft/sqltoolsservice"
},
...
]
Nice!
Getting the Git Metadata
What we basically want to do is to clone the repositories, then get a list of files, get their metadata and finally index the content to our Code Search Service. There are several things we research before starting to write a Powershell script.
We need to clone a Git repository using the git CLI. We don't want to mess up
the current working directory, but clone into some folder. We can do this by
using the git clone command like this:
git clone <repository-url> <repository-directory>
We need a way to find out, which files are actually in version control. We can use git ls-files
to get a list of all files, and we also need to point to our git repository using the --git-dir flag:
git --git-dir "<repository-directory>/.git" ls-files 2>&1
We need a unique identifier for the document. It's a good idea to use the SHA1 hash of the file, that's stored in Git already:
git --git-dir "$repositoryDirectory\.git" ls-files -s $relativeFilepath 2>&1
| ForEach-Object {$_ -Split " "} # Split at Whitespaces
| Select-Object -Skip 1 -First 1
It's important to sort the results by their latest update, which basically is the latest commit
date. This can be done using the git log command and only output the date. Also make sure to use
some kind of Standard formatting, so we can easily parse it on Server-side:
git --git-dir "<repository-directory>\.git" log -1 --date=iso-strict --format="%ad" -- <filename> 2>&1
To create Permalinks for a file, we need its commit hash. We can obtain the SHA1 commit hash by running:
git --git-dir "$repositoryDirectory\.git" log --pretty=format:"%H" -n 1
If you are reading the content of a file in PowerShell with Get-Content it's building a list, instead
of reading it as a single string. So you have to also use the -Raw parameter to get the results as a string:
Get-Content -Path <filename> -Raw
We will build a RESTful endpoint on the server-side, that receives the code documents to index in the JSON format. Converting
a PowerShell object (PSObject) to JSON is done by using the ConvertTo-JSON cmdlet. We need to take special care of escape
handling, because we have multi-line data with control characters, such as \r or \n:
ConvertTo-Json -InputObject <my-input-object> -EscapeHandling EscapeNonAscii
Now we have everything to get started.
PowerShell Script for the Git Indexer
It's just a few lines to go from an idea to an implementation. I have commented each line of the script excessively, so it explains why it has been written the way it is. Be kind, it's my first PowerShell script, so there is surely room to improve.
<#
.SYNOPSIS
Code Indexer for the Elasticsearch Code Search.
#>
function Write-Log {
param(
[Parameter(Mandatory = $false)]
[ValidateSet('Debug', 'Info', 'Warn', 'Error', IgnoreCase = $false)]
[string]$Severity = "Info",
[Parameter(Mandatory = $true)]
[string]$Message
)
$timestamp = Get-Date -Format 'hh:mm:ss'
$threadId = [System.Threading.Thread]::CurrentThread.ManagedThreadId
Write-Output "$timestamp $Severity [$threadId] $Message"
}
function Write-Repository-Log {
param(
[Parameter(Mandatory = $false)]
[ValidateSet('Debug', 'Info', 'Warn', 'Error', IgnoreCase = $false)]
[string]$Severity = "Info",
[Parameter(Mandatory = $true)]
[string]$Repository,
[Parameter(Mandatory = $true)]
[string]$Message
)
$timestamp = Get-Date -Format 'hh:mm:ss'
$threadId = [System.Threading.Thread]::CurrentThread.ManagedThreadId
Write-Output "$timestamp $Severity [$threadId] $Repository $Message"
}
# We are going to use Parallel Blocks, and they don't play nice
# with importing modules and such. It's such a simple function,
# we are just going to source it in each Script Block.
$writeRepositoryLogDef = ${function:Write-Repository-Log}.ToString()
# The AppConfig, where you can configure the Indexer. It allows
# you to set the owner to index, the URL to send documents,
# and whitelist filenames and extensions.
$appConfig = @{
# The organization (or user) we are going to index all repositories
# from. This should be passed as a parameter in a later version ...
Owner = "microsoft"
# We want to index repositories with a maximum of 700 MB initially, so we
# filter all large directories ...
MaxDiskUsageInKilobytes = 100 * 1024
# Maximum Numbers of GitHub Repositories to process. This needs to be
# passed to the gh CLI, because it doesn't support pagination.
MaxNumberOfRepositories = 1000
# Only indexes repositories updated between these timestamps
UpdatedBetween = @([datetime]::Parse("2020-01-01T00:00:00Z"), [datetime]::Parse("9999-12-31T00:00:00Z"))
# Filter for Repositories with the Primary Language
PrimaryLanguage = "C#"
# Set this to false if you want to index archived repositories.
OmitArchivedRepositories = $true
# Set this to true, if you want to index archived repositories only.
OnlyArchivedRepositories = $false
# LogFile to write the logs to. We don't print to screen directly, because
# we cannot trust the results.
LogFile = "C:\Temp\log_indexer.log"
# The Url, where the Index Service is running at. This is the ASP.NET
# Core WebAPI, which is responsible to send the indexing requests ...
CodeSearchIndexUrl = "http://localhost:5000/index-documents"
# This is where we are going to clone the temporary Git repositories to,
# which will be created for reading the file content and sending it to
# the ElasticSearch instance.
BaseDirectory = "C:\Temp"
# Files allowed for processing.
AllowedFilenames = (
".gitignore",
".editorconfig",
"README",
"CHANGELOG"
)
# Extensions allowed for processing.
AllowedExtensions = (
# C / C++
".c",
".cpp",
".h",
".hpp",
# .NET
".cs",
".cshtml",
".csproj",
".fs",
".razor",
".sln",
".xaml",
# CSS
".css",
".scss",
".sass",
# CSV / TSV
".csv",
".tsv",
# HTML
".html",
".htm",
# JSON
".json",
# JavaScript
".js",
".jsx",
".spec.js",
".config.js",
# Typescript
".ts",
".tsx",
# TXT
".txt",
# Powershell
".ps1",
# Python
".py",
# Configuration
".ini",
".config",
# XML
".xml",
".xsl",
".xsd",
".dtd",
".wsdl",
# Markdown
".md",
".markdown",
# reStructured Text
".rst",
# LaTeX
".tex",
".bib",
".bbx",
".cbx"
)
# Batch Size for Elasticsearch Requests.
BatchSize = 30
# Throttles the number of parallel clones. This way we can
# clone multiple repositories in parallel, so we don't have
# to wait for each clone.
MaxParallelClones = 1
# Throttles the number of parallel bulk index requests to
# the backend, so we can send multiple requests in parallel
# and don't need to wait for the request to return.
MaxParallelBulkRequests = 10
}
# Start Writing the Log
Start-Transcript $appConfig.LogFile -Append
# Log Indexer Settings, so we know what configuration had been
# used, when analyzing the Logs.
Write-Log -Severity Debug -Message ($appConfig | ConvertTo-Json)
# Get all GitHub Repositories for an organization or a user, using the GitHub CLI.
$argumentList = @()
$argumentList += "--limit $($appConfig.MaxNumberOfRepositories)"
$argumentList += "--json id,name,owner,nameWithOwner,languages,url,sshUrl,diskUsage,updatedAt"
if($appConfig.OmitArchivedRepositories -eq $true) {
$argumentList += "--no-archived"
}
if($appConfig.OnlyArchivedRepositories -eq $true) {
$argumentList += "--archived"
}
if($appConfig.PrimaryLanguage) {
$argumentList += "--language $($appConfig.PrimaryLanguage)"
}
$arguments = $argumentList -join " "
$cmd = "gh repo list $($appConfig.Owner) $arguments"
Write-Log -Severity Debug -Message "Getting repositories for owner $($appConfig.Owner) using command: '$($cmd)'"
$repositories = Invoke-Expression $cmd
| ConvertFrom-Json
| Where-Object {$_.diskUsage -lt $appConfig.MaxDiskUsageInKilobytes}
| Where-Object { ($_.updatedAt -ge $appConfig.UpdatedBetween[0]) -and ($_.updatedAt -le $appConfig.UpdatedBetween[1]) }
# Add Debug Information about the Number of Repositories to be crawled,
# We could also add the name, but I am unsure about the relevant data.
Write-Log -Severity Debug -Message "Processing $($repositories.Length) repositories"
# Add Debug Information about the Repositories to be indexed. This enables
# us to check the logs, if a repository has been indexed correctly.
Write-Log -Severity Debug -Message "List of Repositories to index: $(($repositories | Select-Object -ExpandProperty name) -join ", ")"
# Index all files of the organization or user, cloning is going to take some time,
# so we should probably be able to clone and process 4 repositories in parallel. We
# need to check if it reduces the waiting time ...
$repositories | ForEach-Object -ThrottleLimit $appConfig.MaxParallelClones -Parallel {
# We need to re-assign the defintion, because we are
# going to have another nested Parallel block, which
# needs to source the function.
$writeRepositoryLogDef = $using:writeRepositoryLogDef
# Source the Write-Repository-Log function, so we can use it in the
# Parallel ScriptBlock. Somewhat ugly, but I don't know a
# good way around.
${function:Write-Repository-Log} = $using:writeRepositoryLogDef
# Get the global AppConfig.
$appConfig = $using:appConfig
# Rename, so we know what we are operating on.
$repository = $_
# Repository Name.
$repositoryName = $repository.name
# Repository URL.
$repositoryUrl = $repository.url
# Repository URL.
$repositoryOwner = $repository.owner.login
# Repository Path.
$repositoryDirectory = "$($appConfig.BaseDirectory)\$repositoryName"
Write-Repository-Log -Severity Debug -Repository $repositoryName -Message "Processing started ..."
# Wrap the whole thing in a try - finally, so we always delete the repositories.
try {
# If the Repository already exists, we don't need to clone it again. This could be problematic,
# when the Repository has been updated in between, but the idea is to re-index the entire
# organization in case of error.
if(Test-Path $repositoryDirectory) {
Write-Repository-Log -Severity Debug -Repository $repositoryName -Message "Directory '$repositoryDirectory' already exists"
} else {
Write-Repository-Log -Severity Debug -Repository $repositoryName -Message "Cloning to '$repositoryDirectory'"
git clone $repositoryUrl $repositoryDirectory 2>&1 | Out-Null
}
# Get all files in the repositrory using the GIT CLI. This command
# returns relative filenames starting at the Repository Path.
$relativeFilepathsFromGit = git --git-dir "$repositoryDirectory/.git" ls-files 2>&1
| ForEach-Object {$_ -Split "`r`n"}
# We get all files, but images and so on are probably too large to index. I want
# to start by whitelisting some extensions. If this leads to crappy results, we
# will try blacklisting ...
$relativeFilepaths = @()
foreach($relativeFilepath in $relativeFilepathsFromGit) {
# Get the filename from the relative Path, we use it to check
# against a set of whitelisted files, which we can read the data
# from.
$filename = [System.IO.Path]::GetFileName($relativeFilepath)
# We need to get the Extension for the given File, so we can add it.
# This ignores all files like CHANGELOG, README, ... we may need some
# additional logic here.
$extension = [System.IO.Path]::GetExtension($relativeFilepath)
# If the filename or extension is allowed, we are adding it to the
# list of files to process. Don't add duplicate files.
if($appConfig.AllowedFilenames -contains $filename) {
$relativeFilepaths += $relativeFilepath
} elseif($appConfig.AllowedExtensions -contains $extension) {
$relativeFilepaths += $relativeFilepath
}
}
Write-Repository-Log -Severity Debug -Repository $repositoryName -Message "$($relativeFilepaths.Length)' files to Process ..."
# We want to create Bulk Requests, so we don't send a million
# Requests to the Elasticsearch API. We will use Skip and Take,
# probably not efficient, but who cares.
$batches = @()
for($batchStartIdx = 0; $batchStartIdx -lt $relativeFilepaths.Length; $batchStartIdx += $appConfig.BatchSize) {
# A Batch is going to hold all information for processing the Data in parallel, so
# we don't have to introduce race conditions, when sharing variables on different
# threads.
$batch = @{
RepositoryName = $repositoryName
RepositoryOwner = $repositoryOwner
RepositoryUrl = $repositoryUrl
RepositoryDirectory = $repositoryDirectory
Elements = @($relativeFilepaths
| Select-Object -Skip $batchStartIdx
| Select-Object -First $appConfig.BatchSize)
}
# Add the current batch to the list of batches
$batches += , $batch
}
Write-Repository-Log -Severity Debug -Repository $repositoryName -Message "'$($batches.Length)' Bulk Index Requests will be sent to Indexing Service"
# Process all File Chunks in Parallel. This allows us to send
# Bulk Requests to the Elasticsearch API, without complex code
# ...
$batches | ForEach-Object -ThrottleLimit $appConfig.MaxParallelBulkRequests -Parallel {
# Source the Write-Repository-Log function, so we can use it in the
# Parallel ScriptBlock. Somewhat ugly, but I don't know a
# good way around.
${function:Write-Repository-Log} = $using:writeRepositoryLogDef
# Get the global AppConfig.
$appConfig = $using:appConfig
# Rename, so we know what we are working with.
$batch = $_
# We need the variables from the outer scope...
$repositoryDirectory = $batch.RepositoryDirectory
$repositoryOwner = $batch.RepositoryOwner
$repositoryName = $batch.RepositoryName
# Holds the File Index Data, that we are going to send
# to Elasticsearch for indexing.
$codeSearchDocumentList = @()
# Each batch contains a list of files.
foreach($relativeFilepath in $batch.Elements) {
# Apparently git sometimes returns " around the Filenames,
# "optimistically" we trim it at the begin and end, and
# hope it works...
$relativeFilepath = $relativeFilepath.Trim("`"")
# We need the absolute filename for the Powershell Utility functions,
# so we concatenate the path to the repository with the relative filename
# as returned by git.
$absoluteFilepath = "{0}\{1}" -f $repositoryDirectory,$relativeFilepath
# Sometimes there is an issue, that the files returned by git are empty
# directories on Windows. Who knows, why? We don't want to index them,
# because they won't have content.
#
# We could filter this out in the pipe, but better we print the problematic
# filenames for further investigation
if(Test-Path -Path $absoluteFilepath -PathType Container) {
Write-Repository-Log -Severity Warn -Repository $repositoryName -Message "The given Filename is a directory: '$absoluteFilepath'"
continue
}
# Totally valid, that GIT returns garbage! Probably a file isn't on disk
# actually, who knows how all this stuff behaves anyway? What should we
# do here? Best we can do... print the problem and call it a day.
if((Test-Path $absoluteFilepath) -eq $false) {
Write-Repository-Log -Severity Warn -Repository $repositoryName -Message "The given Filename does not exist: '$absoluteFilepath'"
continue
}
# Read the Content, that should be indexed, we may
# exceed memory limits, on very large files, but who
# cares...
$content = $null
try {
$content = Get-Content -Path $absoluteFilepath -Raw -ErrorAction Stop
} catch {
Write-Repository-Log -Severity Warn -Repository $repositoryName -Message ("[ERR] Failed to read file content: " + $_.Exception.Message)
continue
}
# Gets the SHA1 Hash of the Git File. We need this to reconstruct the URL to the GitHub
# file, so we have a unique identitfier for the file and we are able to generate a link
# in the Frontend.
$sha1Hash = git --git-dir "$repositoryDirectory\.git" ls-files -s $relativeFilepath 2>&1
| ForEach-Object {$_ -Split " "} # Split at Whitespaces
| Select-Object -Skip 1 -First 1
# We need the Commit Hash for the Permalink and
$commitHash = git --git-dir "$repositoryDirectory\.git" log --pretty=format:"%H" -n 1 -- $relativeFilepath 2>&1
# Get the latest Commit Date from the File, so we
# can later sort by commit date, which is the only
# reason for building this thing...
$latestCommitDate = git --git-dir "$repositoryDirectory\.git" log -1 --date=iso-strict --format="%ad" -- $relativeFilepath 2>&1
# We are generating a Permalink to the file, which is based on the owner, repository, SHA1 Hash
# of the commit to the file and the relative filename inside the repo. This is a good way to link
# to it from the search page, without needing to serve it by ourselves.
$permalink = "https://github.com/$repositoryOwner/$repositoryName/blob/$commitHash/$relativeFilepath"
# The filename with an extension for the given path.
$filename = [System.IO.Path]::GetFileName($relativeFilepath)
# This is the Document, which will be included in the
# bulk request to Elasticsearch. We will append it to
# a list.
#
# Since the Content should be a maximum of 1 MB, we should be on
# the safe side to not have the memory exploding.
$codeSearchDocument = @{
id = $sha1Hash
owner = $repositoryOwner
repository = $repositoryName
path = $relativeFilepath
filename = $filename
commitHash = $commitHash
content = $content
permalink = $permalink
latestCommitDate = $latestCommitDate
}
# Holds all documents to be included in the Bulk Request.
$codeSearchDocumentList += , $codeSearchDocument
}
# Build the actual HTTP Request.
$codeSearchIndexRequest = @{
Method = "POST"
Uri = $appConfig.CodeSearchIndexUrl
Body = ConvertTo-Json -InputObject $codeSearchDocumentList -EscapeHandling EscapeNonAscii # Don't use a Pipe here, so Single Arrays become a JSON array too
ContentType = "application/json"
StatusCodeVariable = 'statusCode'
}
Write-Repository-Log -Severity Debug -Repository $repositoryName -Message "Sending CodeIndexRequest with Document Count: $($codeSearchDocumentList.Length)"
try {
# Invokes the Requests, which will error out on HTTP Status Code >= 400,
# so we need to wrap it in a try / catch block. We can then extract the
# error message.
Invoke-RestMethod @codeSearchIndexRequest | Out-Null
Write-Repository-Log -Severity Debug -Repository $repositoryName -Message "CodeIndexRequest sent successfully with HTTP Status Code = $statusCode"
} catch {
Write-Repository-Log -Severity Error -Repository $repositoryName -Message ("CodeIndexRequest failed with Message: " + $_.Exception.Message)
}
}
}
finally {
if($repositoryDirectory.StartsWith("C:\Temp")) {
Write-Repository-Log -Repository $repositoryName -Severity Debug -Message "Deleting GIT Repository: $repositoryDirectory ..."
Remove-Item -LiteralPath $repositoryDirectory -Force -Recurse
}
}
}
Stop-Transcript
And that's it for the indexer.
Example for indexing an organization
From the projects root we can run the Script with:
.\ElasticsearchCodeSearch\ElasticsearchCodeSearch.Indexer\git_indexer.ps1
The Script writes a Log to C:\Temp\log_indexer.log, so we can see what's happening:
Transcript started, output file is C:\Temp\log_indexer.log
12:38:00 Debug [20] {
"AllowedExtensions": [
".c",
".cpp",
".h",
".hpp",
".cs",
".cshtml",
".csproj",
".fs",
".razor",
".sln",
".xaml",
".css",
".scss",
".sass",
".csv",
".tsv",
".html",
".htm",
".json",
".js",
".jsx",
".spec.js",
".config.js",
".ts",
".tsx",
".txt",
".ps1",
".py",
".ini",
".config",
".xml",
".xsl",
".xsd",
".dtd",
".wsdl",
".md",
".markdown",
".rst",
".tex",
".bib",
".bbx",
".cbx"
],
"PrimaryLanguage": "C#",
"OnlyArchivedRepositories": false,
"MaxParallelBulkRequests": 10,
"MaxNumberOfRepositories": 1000,
"LogFile": "C:\\Temp\\log_indexer.log",
"AllowedFilenames": [
".gitignore",
".editorconfig",
"README",
"CHANGELOG"
],
"BaseDirectory": "C:\\Temp",
"OmitArchivedRepositories": true,
"CodeSearchIndexUrl": "http://localhost:5000/index-documents",
"UpdatedBetween": [
"2020-01-01T01:00:00+01:00",
"9999-12-31T01:00:00+01:00"
],
"MaxDiskUsageInKilobytes": 102400,
"Owner": "microsoft",
"BatchSize": 30,
"MaxParallelClones": 1
}
12:38:00 Debug [20] Getting repositories for owner microsoft using command: 'gh repo list microsoft --limit 1000 --json id,name,owner,nameWithOwner,languages,url,sshUrl,diskUsage,updatedAt --no-archived --language C#'
12:38:37 Debug [20] Processing 662 repositories
12:38:37 Debug [20] List of Repositories to index: semantic-kernel, kiota, ...
12:38:39 Debug [167] semantic-kernel Processing started ...
12:38:39 Debug [167] semantic-kernel Cloning to 'C:\Temp\semantic-kernel'
12:38:42 Debug [167] semantic-kernel 1335' files to Process ...
12:38:43 Debug [167] semantic-kernel '45' Bulk Index Requests will be sent to Indexing Service
12:38:45 Debug [169] semantic-kernel Sending CodeIndexRequest with Document Count: 30
12:38:45 Debug [172] semantic-kernel Sending CodeIndexRequest with Document Count: 30
12:38:45 Debug [174] semantic-kernel Sending CodeIndexRequest with Document Count: 30
12:38:45 Debug [173] semantic-kernel Sending CodeIndexRequest with Document Count: 30
12:38:46 Debug [161] semantic-kernel Sending CodeIndexRequest with Document Count: 30
12:38:46 Debug [157] semantic-kernel Sending CodeIndexRequest with Document Count: 30
12:38:46 Debug [158] semantic-kernel Sending CodeIndexRequest with Document Count: 30
12:38:46 Debug [153] semantic-kernel Sending CodeIndexRequest with Document Count: 30
12:38:46 Debug [155] semantic-kernel Sending CodeIndexRequest with Document Count: 30
12:38:46 Debug [172] semantic-kernel CodeIndexRequest sent successfully with HTTP Status Code = 200
12:38:46 Debug [156] semantic-kernel Sending CodeIndexRequest with Document Count: 30
12:38:46 Debug [173] semantic-kernel CodeIndexRequest sent successfully with HTTP Status Code = 200
12:38:46 Debug [174] semantic-kernel CodeIndexRequest sent successfully with HTTP Status Code = 200
12:38:46 Debug [156] semantic-kernel CodeIndexRequest sent successfully with HTTP Status Code = 200
12:38:47 Debug [169] semantic-kernel CodeIndexRequest sent successfully with HTTP Status Code = 200
12:38:47 Debug [153] semantic-kernel CodeIndexRequest sent successfully with HTTP Status Code = 200
12:38:47 Debug [161] semantic-kernel CodeIndexRequest sent successfully with HTTP Status Code = 200
12:38:47 Debug [158] semantic-kernel CodeIndexRequest sent successfully with HTTP Status Code = 200
12:38:47 Debug [155] semantic-kernel CodeIndexRequest sent successfully with HTTP Status Code = 200
12:38:47 Debug [157] semantic-kernel CodeIndexRequest sent successfully with HTTP Status Code = 200
12:38:49 Debug [201] semantic-kernel Sending CodeIndexRequest with Document Count: 30
12:38:49 Debug [201] semantic-kernel CodeIndexRequest sent successfully with HTTP Status Code = 200
12:38:49 Debug [145] semantic-kernel Sending CodeIndexRequest with Document Count: 30
12:38:49 Debug [148] semantic-kernel Sending CodeIndexRequest with Document Count: 30
12:38:49 Debug [65] semantic-kernel Sending CodeIndexRequest with Document Count: 30
12:38:49 Debug [145] semantic-kernel CodeIndexRequest sent successfully with HTTP Status Code = 200
12:38:49 Debug [148] semantic-kernel CodeIndexRequest sent successfully with HTTP Status Code = 200
12:38:49 Debug [65] semantic-kernel CodeIndexRequest sent successfully with HTTP Status Code = 200
12:38:50 Debug [203] semantic-kernel Sending CodeIndexRequest with Document Count: 30
PS C:\Users\philipp\source\repos\bytefish\SimpleCodeSearch>
Conclusion
So we now have a Git indexer, that allows us to index files of Git repositories. We can easily
include file extensions and filenames by modifying the whitelists in the configuration. Using the ForEach-Object -Parallel
switch, it's possible to parallelize the indexing pipeline and make better use of resources.